

Retrieval Augmented Generation (RAG) - A Simple Theoretical Introduction.
LLM: What new information can I use?


Introduction
Over the last year, the popularity of Large Language Models (LLMs) has soared significantly, with use cases in almost all major industries popping up, mostly through chat interfaces or chatbots. With this popularity, the question of how to keep them updated became a concern because LLMs inherently are meant to spit out some sequence of text based on some internal rules learned during training, and this knowledge is limited to the point of training.
Many techniques can be used to update a model, but one, it can get very expensive (money) to continuously train a model, and two, even with the "cheapest" technique being, fine-tuning, a form of transfer learning, the barrier of entry is quite high for non-technical folks.
To alleviate this "outdatedness", Retrieval-Augmented Generation (RAG), a technique for effectively enhancing LLMs with external facts can be used to better answer some questions. In simple terms, the techinque is similar to going to a library to search for resources or books so that you can not only use your stored knowledge on a topic for instance, to write an essay, but also have external references to boost it.
Next, we'll use a simple flow diagram to explain in a nutshell, how RAG works with LLMs.
Architecture
Flow Chart
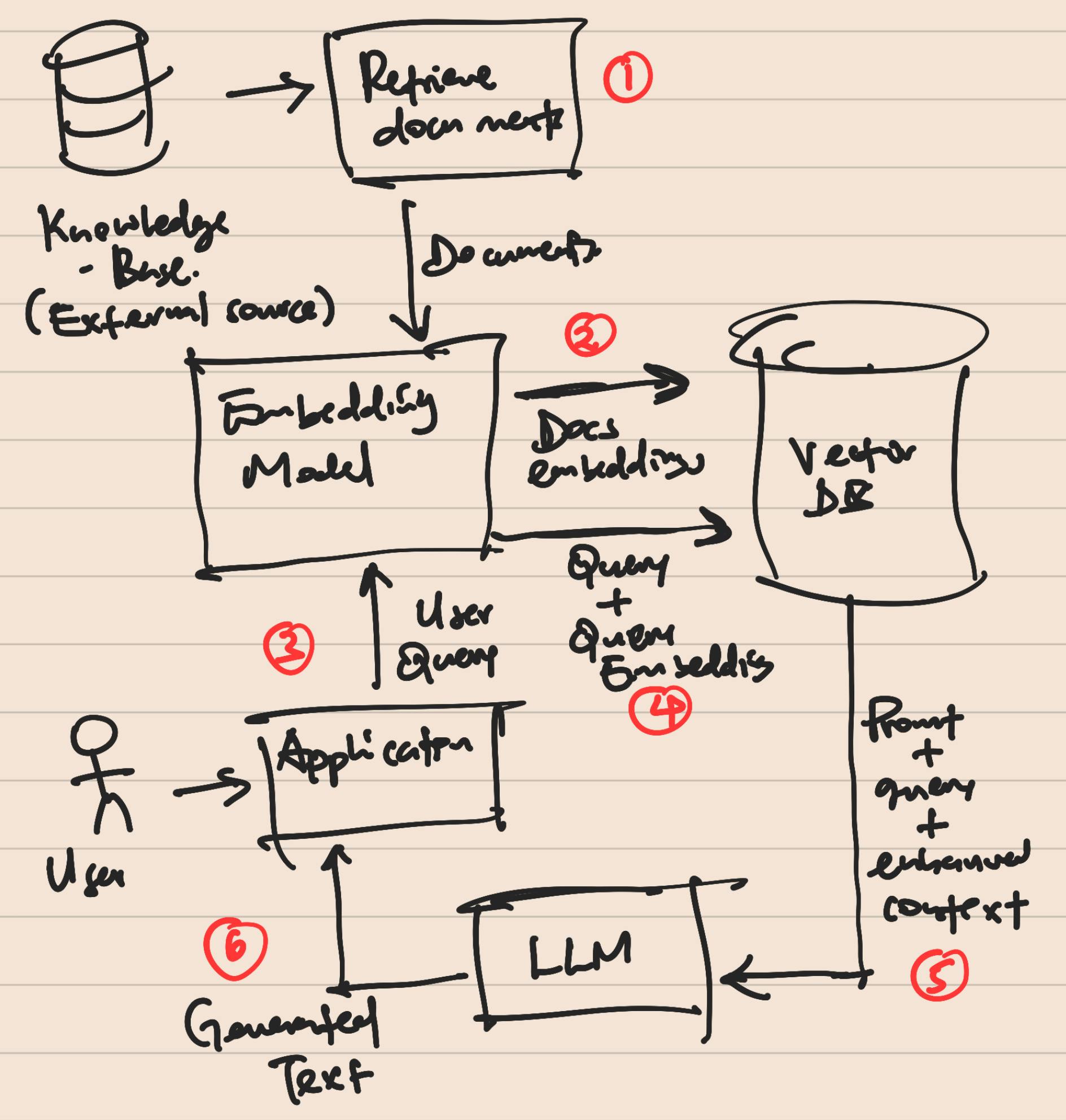
Explanation
This section explanation is inherently split into two; (1, 2) - Pre-user interaction. (3,4,5,6) - During user interaction with the LLM/Chatbot interface.
Retrieve the latest documents or document chunks from your Knowledge Base / Database.
Use an embedding model to generate document embeddings/vectors and store them in a Vector DB.
Get user query and send it to embedding model to generate query embeddings.
Perform a similarity search in your Vector DB between the query embedding and document embeddings, and return top-k similar documents. These will form the context for your LLM.
Combine the user query with the context by generating an enhanced prompt and send that to the LLM.
Return results to the user.
The above steps form a typical flow of events in a system/pipeline using RAG and LLMs. Also, note that the Vector DB is always kept up to date with new documents from your Knowledge Base.
Conclusion
Even though using RAGs minimizes the cost (money) it would take to continuously retrain an LLM, it still has some hidden and potentially significant costs i.e.
The inference latency may increase as the pipeline involves two new steps (a- using an embedding model that has its latency, and b - performing a similarity search on the Vector DB may take some time).
Having another model endpoint (embedding model) running especially in the cloud might incur some credits (this is specific to the architecture, environment, or tools you choose to use in your deployments).
The strategy used to chunk or split your documents may affect the accuracy or correctness of the responses you get. So some complexity costs might be experienced here. Libraries such as LangChain can help with this.
The choice of which LLM variant (7B, 13B, 70B) to use in your pipeline may also inflate some of the above challenges.
All in all, as LLMs continue to become mainstream, the technology enhancements for RAGs will most definitely come up that will help mitigate these challenges, so keep exploring and hacking!
References
https://github.com/nerdai/talks/blob/main/2024/mlops/mlops-rag-bootcamp.ipynb (Easy to follow practical use case)
nvidia.com/en-gb/ai-on-rtx/chat-with-rtx-ge..
https://python.langchain.com/docs/use_cases/question_answering/quickstart/
https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/